Jak wykorzystać informacje o miejscu i roli autora w sieci społecznościowej do lepszej detekcji trolli?
Każdy autor jest częścią sieci. Węzłem, połaczonym z innymi węzłami.
Wiemy z iloma użytkownikami sieci jest połączony i ilu jest połaczonych z nim.
Wiemy jak sieć przekazuje jego treści i jak on przekazuje inne treści.
To conajmniej kilkanaście atrybutów, potencjalnie istotnych do detekcji treści fałszywych. Nawet zaczynając od podstawowych miar
Network Sciencemamy bogaty opis węzłów sieci. Dane do tego opisu są dostępne z twittera i mogą być scrapowane razem z treścią.
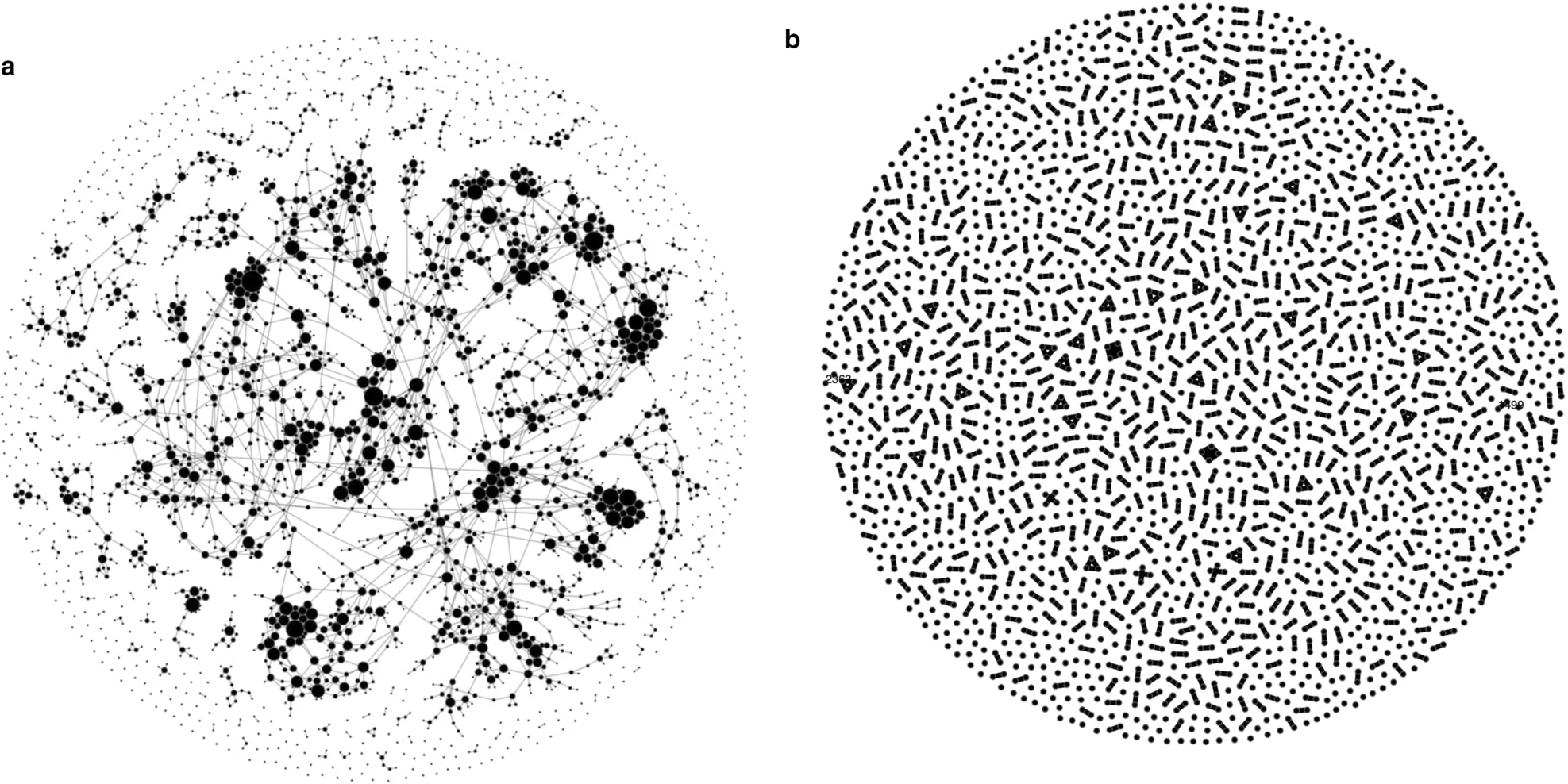
- Każdy tweet/post ma swoje
źródło(autora) idrzeworozpstrzestrzeniania (retweety, forwardy, re-posty). - Atrybuty sieciowe autora, np.:
- degree - liczba followersów in/out;
- egonet - liczba followersów w 2gim rzędzie (followersi followersów);
- bilans - follows/following;
- clique - jak bardzo jego sieć jest zamknięta - parametry
community;
- Artybuty node'ów:
- liczba postów
- liczba likeów/retweetów/commentów na post
- średnia, odchylenie, zmienności atrybutów
- dynamika zmian w czasie (przyrost treści i rozrost sieci).
- Te atrybuty można określic dla sieci autora (jego znajomych) i agregować dla węzła.
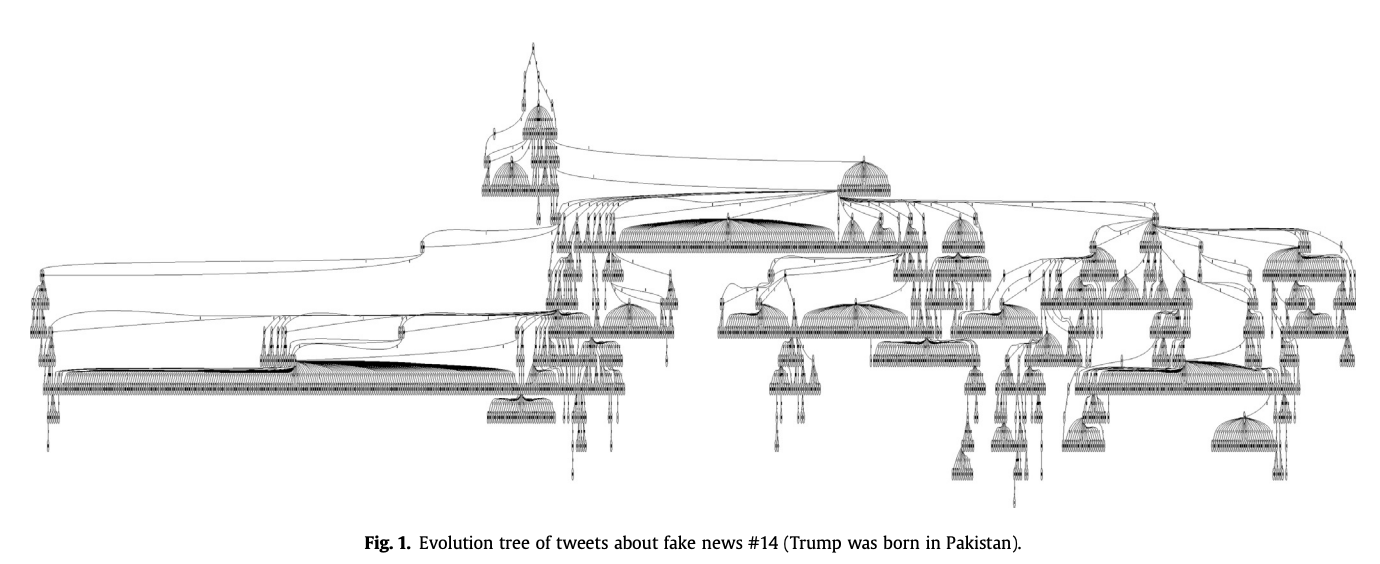
Każda treść ma swoje źródło i od niego rozchodzi się docierając do nowych użytkowników. Proces rozprzestrzeniania (drzewo) można opisać miarami sieciowymi (głębokość, szerokość, zmiennośc, itp.). Jest kilka przykładów jak po kształcie takiego drzewa można rozróżniać tweety fałszywe.
- Wykorzystanie:
- Mogą to być dodatkowe labelki dla algorytmów, istotne, albo nieistotne dla detekcji.
- Możemy zrobić tutaj analizę istotności statystycznej nowych lalelków dla detekcji.
- Możemy zrobić np. PCA i zrobic jakis synetytczną miarę używaną przy uczeniu.
- Mozemy zacząc od prostych analiz (EDA) jakie atrybuty są dla treści prawdziwych, jakie dla fałyszywych i sprawdzić czy jest coś istotnie różnego.
- Problemy:
- twint - mnie nie działa... próbowałem kilka razy,
- zbiór treningowy - fake vs. real - labelled: https://www.kaggle.com/search?q=troll+in%3Adatasets
- Literatura:
- Tomaiuolo, M., Lombardo, G., Mordonini, M., Cagnoni, S., & Poggi, A. (2020). A survey on troll detection. Future internet, 12(2), 31. https://www.mdpi.com/1999-5903/12/2/31
- Fornacciari, Paolo, Monica Mordonini, Agostino Poggi, Laura Sani, and Michele Tomaiuolo. "A holistic system for troll detection on Twitter." Computers in Human Behavior 89 (2018): 258-268. https://doi.org/10.1016/j.chb.2018.08.008
- Sun, Qiusi, and Cuihua Shen. "Who would respond to A troll? A social network analysis of reactions to trolls in online communities." Computers in Human Behavior 121 (2021): 106786. https://doi.org/10.1016/j.chb.2021.106786
- Wu, Z., Aggarwal, C. C., & Sun, J. (2016, February). The troll-trust model for ranking in signed networks. In Proceedings of the Ninth ACM international conference on Web Search and Data Mining (pp. 447-456). https://dl.acm.org/doi/abs/10.1145/2835776.2835816
- Saeed, Mohammad Hammas, Shiza Ali, Jeremy Blackburn, Emiliano De Cristofaro, Savvas Zannettou, and Gianluca Stringhini. "TROLLMAGNIFIER: Detecting State-Sponsored Troll Accounts on Reddit." arXiv preprint arXiv:2112.00443 (2021). https://arxiv.org/abs/2112.00443
- Jang, S. Mo, Tieming Geng, Jo-Yun Queenie Li, Ruofan Xia, Chin-Tser Huang, Hwalbin Kim, and Jijun Tang. "A computational approach for examining the roots and spreading patterns of fake news: Evolution tree analysis." Computers in Human Behavior 84 (2018): 103-113. https://doi.org/10.1016/j.chb.2018.02.032
- Grinberg, Nir, Kenneth Joseph, Lisa Friedland, Briony Swire-Thompson, and David Lazer. "Fake news on Twitter during the 2016 US presidential election." Science 363, no. 6425 (2019): 374-378.https://www.science.org/doi/full/10.1126/science.aau2706?casa_token=FiOAkRUw-E4AAAAA%3AmcjY-ysgVEpPX4HwD5DCXPgxQ9zKdxEM3R0La2rm98UDKU-sVrqMnbMikFET6BEagoBuFotgG8Wak-Q