The Attention mechanism in Deep Learning is based off the concept of directing model's focus, and it pays greater attention to certain factors when processing the data.[1]

Attention Mechanism enables the deep learning model to identify which part of the input has more or which part has less significance for predicting the output. To enable this we define a extra set of functions that captures the importance of the region in Input vector/tensor, then we normalize that state using softmax function.
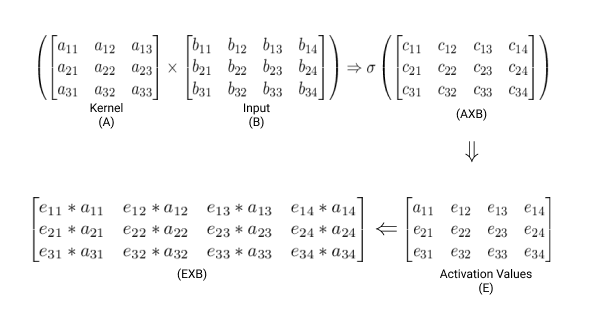
Attention Mechanism has these three base equation in most of the case you just have to take care of the activation funtion and dimentions.
X : Input Tensor
Y : Output Tensor
W : Weight Matrix
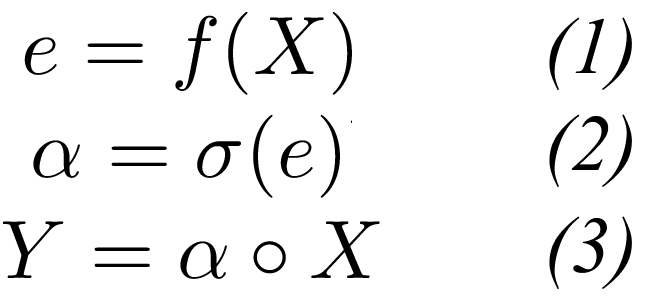
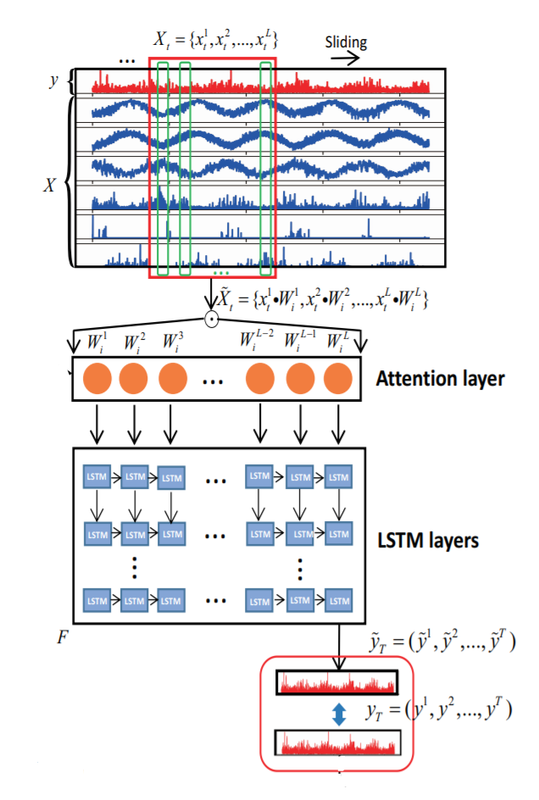
Below is the Naive implementation of Attention mechanism, I created a attention layer as a precursor to the LSTM layer that defines which of the input features and history is important. for complete implementation checkout github repo here
NOTE: Advanced Implementation coming soon...🚄
source) https://arxiv.org/abs/1811.03760
These matrix operation are applied in the AttentionModule layer see code below